Ninety Percent Coding
Mar. 7, 2026
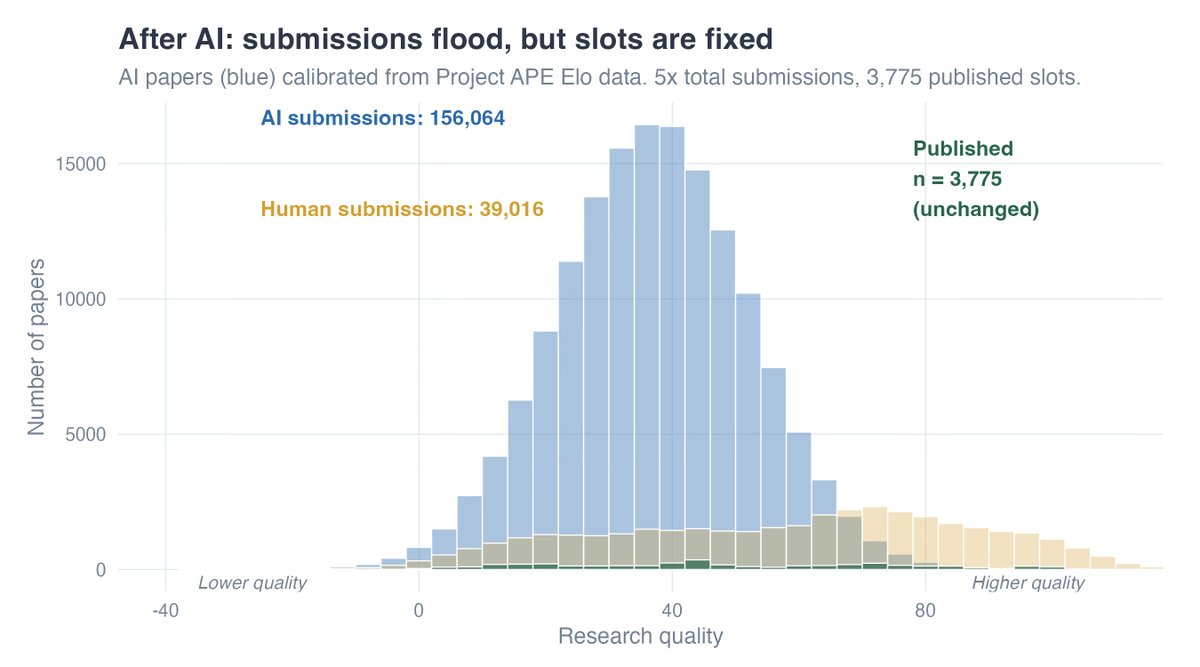
Ben Moll linked to a Causal Inference blog post with this graphic raising questions of supply and demand imbalances.
Others have chimed in. It is fun to speculate on the future of our field at the onset of a small revolution.1 I couldn’t find the source, but it is by now enough of a cliche among software engineers to think about a 90/10 model of coding: agents get 90% of the job done, but humans are still needed to orchestrate and handle the finicky last 10%.
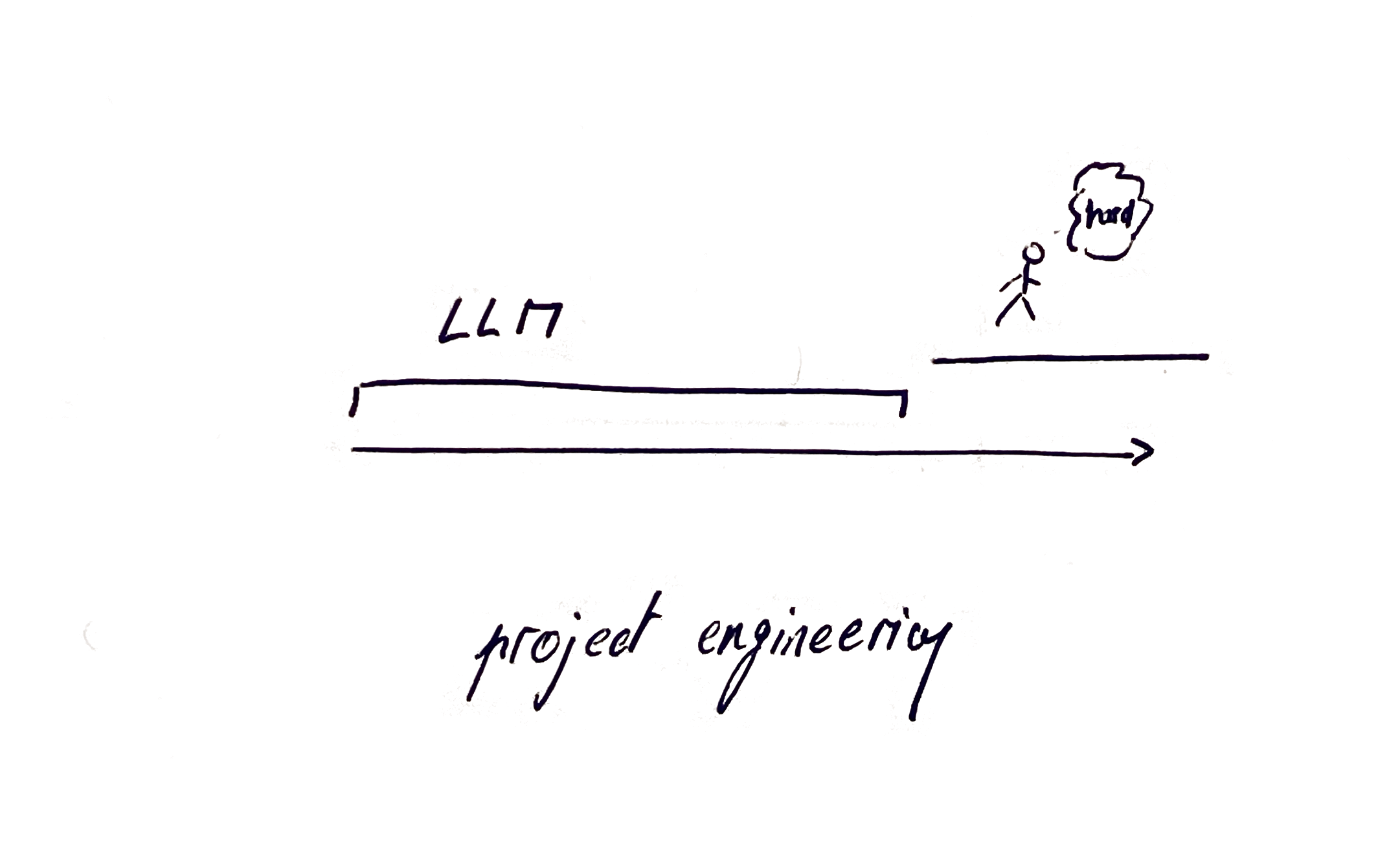
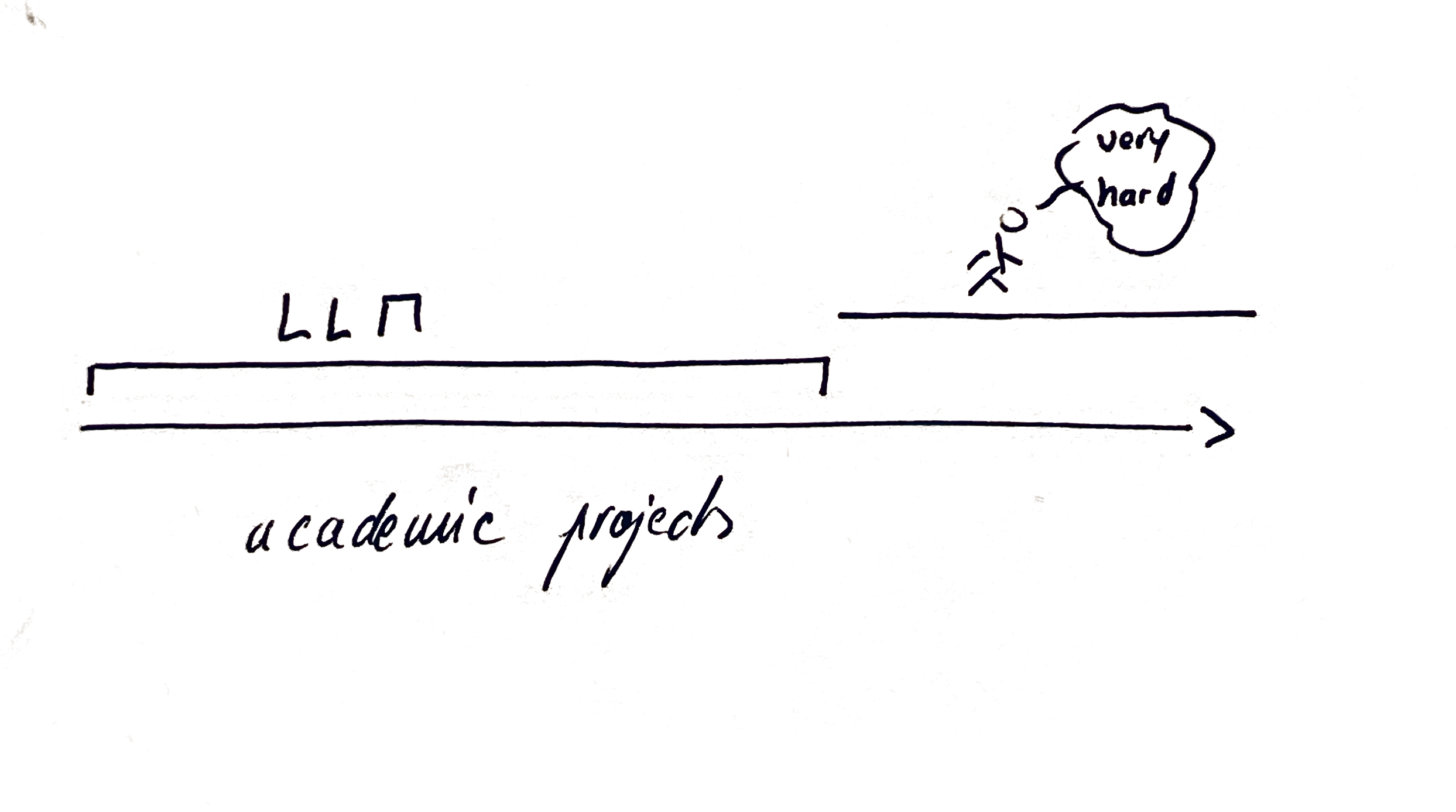
Academics have different objective functions. Most of the time they are their own clients of the data pipeline or model they are coding, and most of the projects are single use. My point is that most of the time, my work falls well within the 90% that LLMs handle comfortably.2
So how does this change things? When the cost of producing a certain type of research drops, we get more of it. But the the consumption of research is fixed right now. Rather than an increase in the quantity, we probably should expect a change in the type of research coming out.
I have two models in mind that define a broad spectrum of what could happen.
- We start trying more things. A thousand blooming flowers. We discover more things in the process. Quality stays roughly the same. We don’t feel compelled to publish tepid stuff.
- We do harder things. Maybe we add one more state variable (or two) in a macrofinance model or we just push existing projects a little further. One idea I like: we turn our code into libraries for others to use. We move from single-use research process to something more collaborative. The cost of polishing code so someone else can actually use it is now low.3

Scott Cunningham’s blog is paywalled, so I am doomed to live in the fear of badly paraphrasing his wisdom. ↩︎
I am speaking for my field of financial economics, maybe economics more broadly, which is heavily empirical. If you are studying theoretical computer science, this probably does not apply or does in surprising ways. ↩︎
Replication packages are so uptight that they are not really good at fostering code reuse and libraries. They are literally containers that run a paper. ↩︎